AOC23 - 5 December
2023-12-5
Good morning! After mesmerizing somewhat over the nostalgia of the new GTA 6 set in the original Vice City, and planning my working day a bit, it is time to have a look at today's puzzle. It is long. That is the first thing I noticed.
The Problem
An almaniac seems to be a document published in regular intervals containing some domain-specific information. Like an OG Newsletter. Mostly about weather forecast, planting dates, etc...

Ok with that bit of trivia out of the way, let's analyze the prompt.
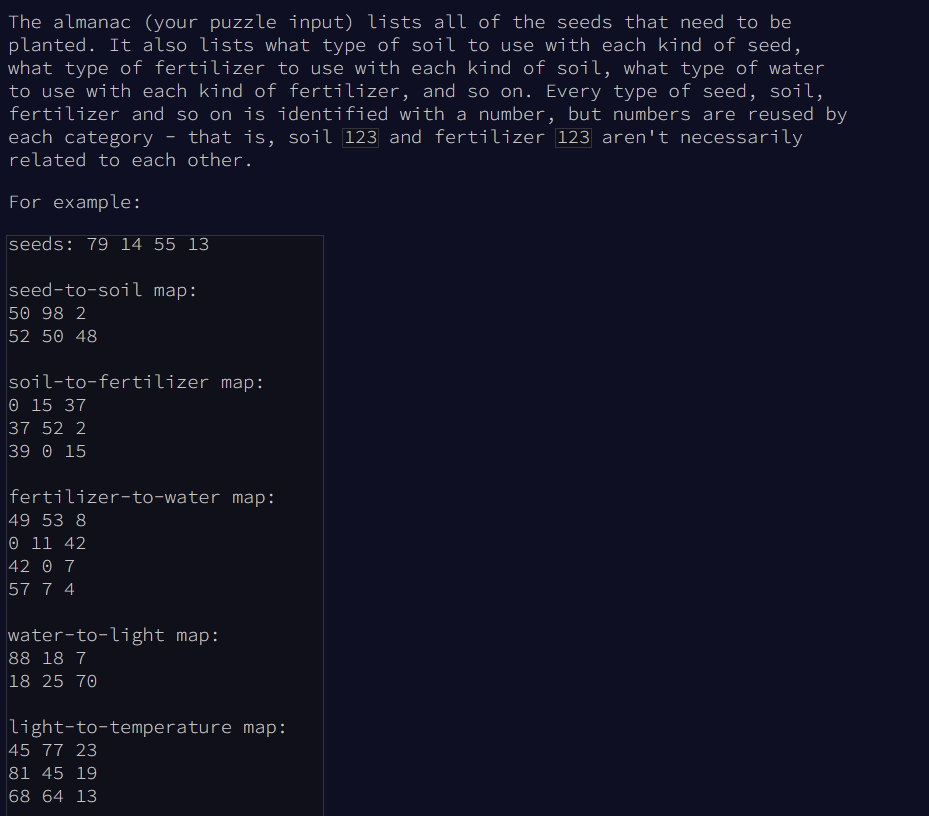
- There is different kind of seeds that need to be planted
- Each seed has associated Soil
- Soil has associated fertelizer
- And fertelizer has associated water, and so on...
- Seed, water, soil and fertilizer reside in their own numbered categories identified by a number
The instruction list tells us:
- Which seeds need to be planted
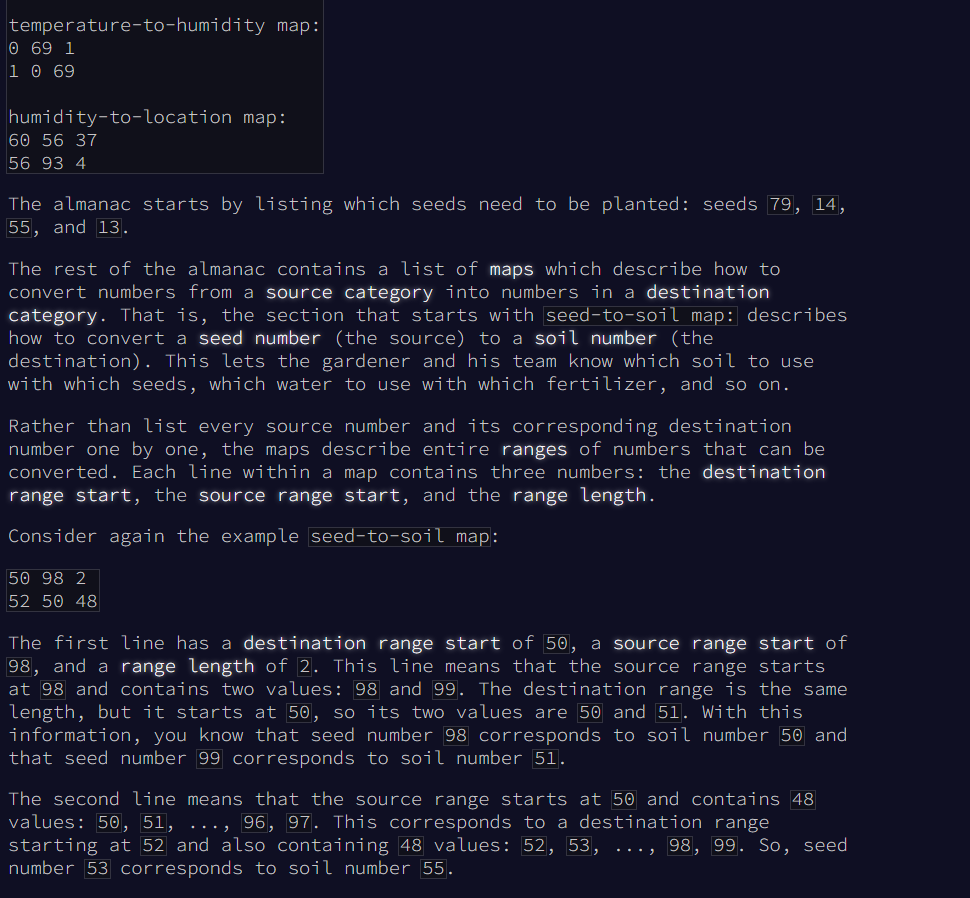
- And then a series of maps from one category to the next
- The maps are expressed in terms of ranges. The first number is the destination range start, the second number is the source range start and the last number is the range length
- The collection of numbers in the specific destination and source range are mapped 1:1
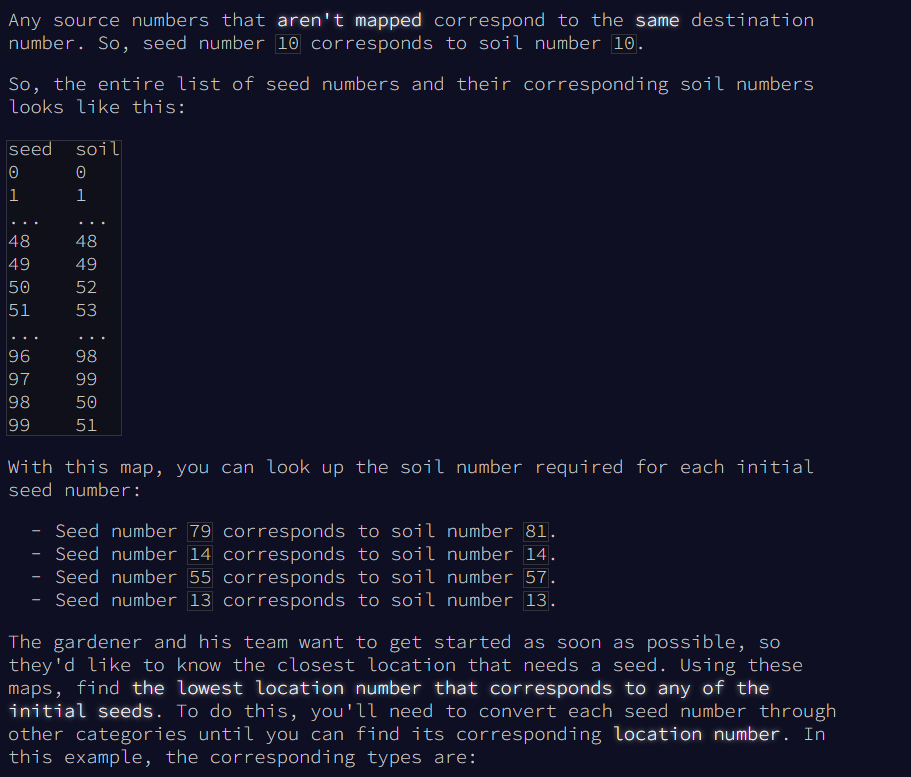
- Any none mapped numbers have corresponding source and destination numbers
- However only those free starting by 1 put face to face. Let's say the source has already used up 18-20 for a previous mapping and the destination still has 18-20, than in the unmapped range destination 21-22 may correspond to 18-20. This requires us to make a linear list and drop out the taken ranges.
Ok this is the nature of our data and data structures. Now we come to the actual problem.
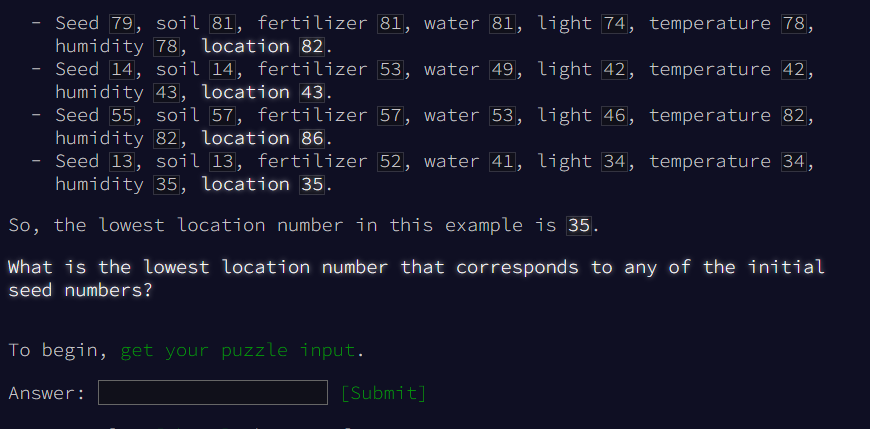
- We need to find the lowest location number that corresponds to one of the initially listed seeds
In relation to the context information the actual problem statement is short and to the point.
Fascinating.
Reasoning about the problem
Alrighty, so we need to:
- Parse the Almanac
- Exctract the list of seeds
- Build a clever and efficient mapping of categories (hahaha, lol - One day later)
- For each seed do a traversal of that mapping
- And get the minimum of the resulting map of seed to location
I have learned my lesson. After chugging down half a liter of black tea and swallowing a cigarette standing outside gazing at the traffic, I had enough time to ponder.
I think this time the type system of languages like Elm will shine, helping me not to lose track of the relationships. So let's model the data.
Now instinctively I would like to Assign Seed, Soil, Water, etc... as type aliases for Int. But then I will not be able to freely reuse functions to map keys to values, because they would all be different types. And as far as I know elm does not support type classes for some good old polymorphism. So I might want to look into that before locking me into some kind of type jail.
I have to make a test first.
> type alias Seed = Int
> a : Seed
| a = 12
12 : Seed
> 12
12 : number
> a
12 : Seed
> a + 12
24 : Int
> b = {a = 11}
{ a = 11 } : { a : number }
> .a b
11 : number
> import Dict
> Dict.fromList [(a, 22)]
Dict.fromList [(12,22)]
: Dict.Dict Int number
> c = Dict.fromList [(a, 22)]
Dict.fromList [(12,22)]
: Dict.Dict Int number
> Dict.get 12 c
Just 22 : Maybe number
Ok so, I've found out a few things. If I define a type alias, it is just that, a coating for something that is actually Int. So my original plan of assigning each of the involved categories a type alias to keep them organized in my mind, will work. Also we can use those type aliases as dictionaries (aka Hash maps) to map them. This also tells me that I will be working under the type of Maybe. Instead of trying to resolve it after each operation this time I will structure most of my code in the context of Maybe.
type alias Seed = Int
type alias Soil = Int
type alias Fertilizer = Int
type alias Water = Int
type alias Light = Int
type alias Temperature = Int
type alias Humidity = Int
type alias Location = Int
type alias Range = (Int, Int)
type alias Mapping = Dict Int Int
Equipping myself with the right tools
To build a Dict we need to use Lists:
fromList : List ( comparable, v ) -> Dict comparable v
So this is a good use-case for zip. However I just realized that List does not implement 'zip' only 'unzip', what is going on?
After a quick research it turns out that zip is easily implemented as
zip = List.map2 Tuple.pair
And also that many additional things are implemented in the "Extra" libraries from the community.
I will go down that route just to get used to the ecosystem and namespacing.
import List.Extra as List
Importing it like this just expands my List namespace and I can simply use all the list utility by prefixing it with "List". I am going to do it with Maybe and Dict aswell, just to be well equipped.
This will be the key function
traverse : Seed -> Maybe Location
traverse s = Just 0
This also shows me a problem. I need to find a way to store the collection of mappings. I think I am going to browse the Extra libraries and can see if I find an idiomatic way to store them.
dropWhile : (a -> Bool) -> List a -> List a
This is going to be helpful already
removeIds : List (Int, Int) -> List Int -> List Int
removeIds listOfDestinationsAndSources fullRange = []
With this function I am going to remove the taken keys and values from the mappings.
Next the parsing. I wanted to look into the built-in parsing library and compare it with Regex, to see if this time I have an easier time. We are after all parsing a very rudimentary declarative domain-specific language. From their websitethey say this:
Regular expressions are quite confusing and difficult to use. This library provides a coherent alternative that handles more cases and produces clearer code.
The particular goals of this library are:
- Make writing parsers as simple and fun as possible.
- Produce excellent error messages.
- Go pretty fast.
I love learning new APIs, so lets dive in. So from what I gather I can define a pipeline of "|." (ignore incoming character) and "|=" take incoming character. It does not support backtracking by default, which I can understand. I will read a bit more into it.
Oh wow, so parser is very close to the domain of parsing programming languages, implementing concept such as variables, keywords and tokens as an example. Maybe this is a bit overkill for my needs?
My answer for now is Yes. Let's look for other options.
Parsing
Today we have as usual a text organized in lines, however we also have blocks divided by double line breaks to add an additional layer of complexity. I have a feeling that this trend will continue in the future. So it is good that I had a look at the parser for future needs. Today I will try to solve it with regex still.
Let's break down our code.
I think for future convention I will add a pendant to my Model type called Structure, which always reflects my parsed data. Keeping it abstract enough for all sorts of problems but avoiding calling it as ambiguous as "data". I will store structure inside my update as variable and pass it to whatever function needs it.
While thinking about the structure of my data I realized that I will probably be working with a list of mappings, and have a sequence of steps in a pipeline as an abstraction to model rather than having to care about whether it is a Seed, Water, Soil, etc.. So I am going to change my Data modeling a bit now.
type Thing =
Seed
| Soil
| Fertilizer
| Water
| Light
| Temperature
| Humidity
| Location
pipeline : List Thing
pipeline = [Seed, Soil, Fertilizer, Water, Light, Temperature, Humidity, Location]
pipelineIndex : Thing -> Maybe Int
pipelineIndex t = List.elemIndex t pipeline
To challenge myself I created a little function that based on an ordered list of Things creates the mapping of related Things.
relation : Dict Thing Thing
relation =
pipeline |>
List.foldr
(\a b ->
let (toMatch, relations) = b
in
case (toMatch) of
Nothing -> (Just a, relations)
Just t -> (Just a, List.append [(a, t)] relations)
(Nothing, []) |>
Tuple.second |>
Dict.fromList
> relations: [(Seed,Soil),(Soil,Fertilizer),(Fertilizer,Water),(Water,Light),(Light,Temperature),(Temperature,Humidity),(Humidity,Location)]
With that out of the way, I am done with parsing.
parse : String -> Structure
parse str =
let
blocks = String.split "\n\n" str
seedsBlock = List.head blocks |> Maybe.withDefault ""
mapps = Dict.fromList <| Maybe.values <| List.map parseMapping <|
Maybe.withDefault [] <| List.tail blocks
in
{ seeds = parseNum seedsBlock
, mappings = mapps
}
parseNum : String -> List Int
parseNum str =
let regexNum =
Maybe.withDefault Regex.never <|
Regex.fromString "\\d+"
in
Regex.find regexNum str |>
List.map .match |>
Maybe.traverse String.toInt |>
Maybe.withDefault []
listPairMap : (a -> (b, c)) -> List a -> (List b, List c)
listPairMap f l = List.foldl (\a b ->
let
(firstList, secondList) = b
(result1, result2) = f a
in
( List.append firstList <| [result1]
, List.append secondList <| [result2])
) ([], []) l
parseMapping : String -> Maybe ((Thing, Thing), Dict Int Int)
parseMapping str =
let
lines = String.lines str
title =
List.head lines |>
Maybe.withDefault "" |>
String.trim |>
String.split "-to-" |>
listToPair |>
Maybe.withDefault ("", "") |>
tupleMap parseThing |>
traversePair
ranges =
List.tail lines |>
Maybe.withDefault [] |>
List.map parseNum |>
List.map listToRange |>
Maybe.values |>
List.map rangeToMapping |>
List.concat
in
Maybe.andThen
(\a -> Just (a, Dict.fromList ranges))
title
traversePair : (Maybe a, Maybe a) -> Maybe (a, a)
traversePair t =
case t of
(Just a, Just b) -> Just (a, b)
_ -> Nothing
listToPair : List a -> Maybe (a, a)
listToPair l =
case l of
[a, b] -> Just (a, b)
_ -> Nothing
listToRange : List Int -> Maybe Range
listToRange l =
case l of
[a, b, c] -> Just ((a, b), c)
_ -> Nothing
rangeToMapping : Range -> List (Int, Int)
rangeToMapping r =
let ((from, to), range) = r
in
List.zip (List.range from (from + range)) (List.range to (to + range))
tupleMap : (a -> b) -> (a, a) -> (b, b)
tupleMap f t =
let
(a, b) = t
in (f a, f b)
parseThing : String -> Maybe Thing
parseThing str =
case str of
"seed" -> Just Seed
"soil" -> Just Soil
"fertilizer" -> Just Fertilizer
"water" -> Just Water
"light" -> Just Light
"temperature" -> Just Temperature
"humidity" -> Just Humidity
"location" -> Just Location
_ -> Nothing


Somehow Seed -> Soil is not working
fullMapping =
List.zip
(List.range 0 highestNum |> List.filterNot (existingValues ranges Tuple.first))
(List.range 0 highestNum |> List.filterNot (existingValues ranges Tuple.second)) |>
List.append ranges
this was a problem of deceptiveness of the "dropWhile" function. As soon as it hits a positive result it stops the entire iteration, while filterNot (the more suitable option here) is just a filter with a not put in front of the entrance.
Solving by Cross-referencing
To solve it, I know need to walk down from relation map to relation map jumping from possible ID matches to the next, till I get to a location.
solve1 : Structure -> Int
solve1 str =
List.map (traverse str.mappings) str.seeds |>
Maybe.values |>
List.minimum |>
Maybe.withDefault 0
solve2 : Structure -> Int
solve2 str = 0
traverse : Mapping -> Int -> Maybe Int
traverse maps s =
List.foldl mapId (Just s) <| Dict.values maps
mapId : Dict Int Int -> Maybe Int -> Maybe Int
mapId dic index =
Maybe.andThen (\i -> Dict.get i dic) index
I think this is quite the elegant solution. However when I apply to the sample data, it does not return the correct result, eventho in traverses correctly.
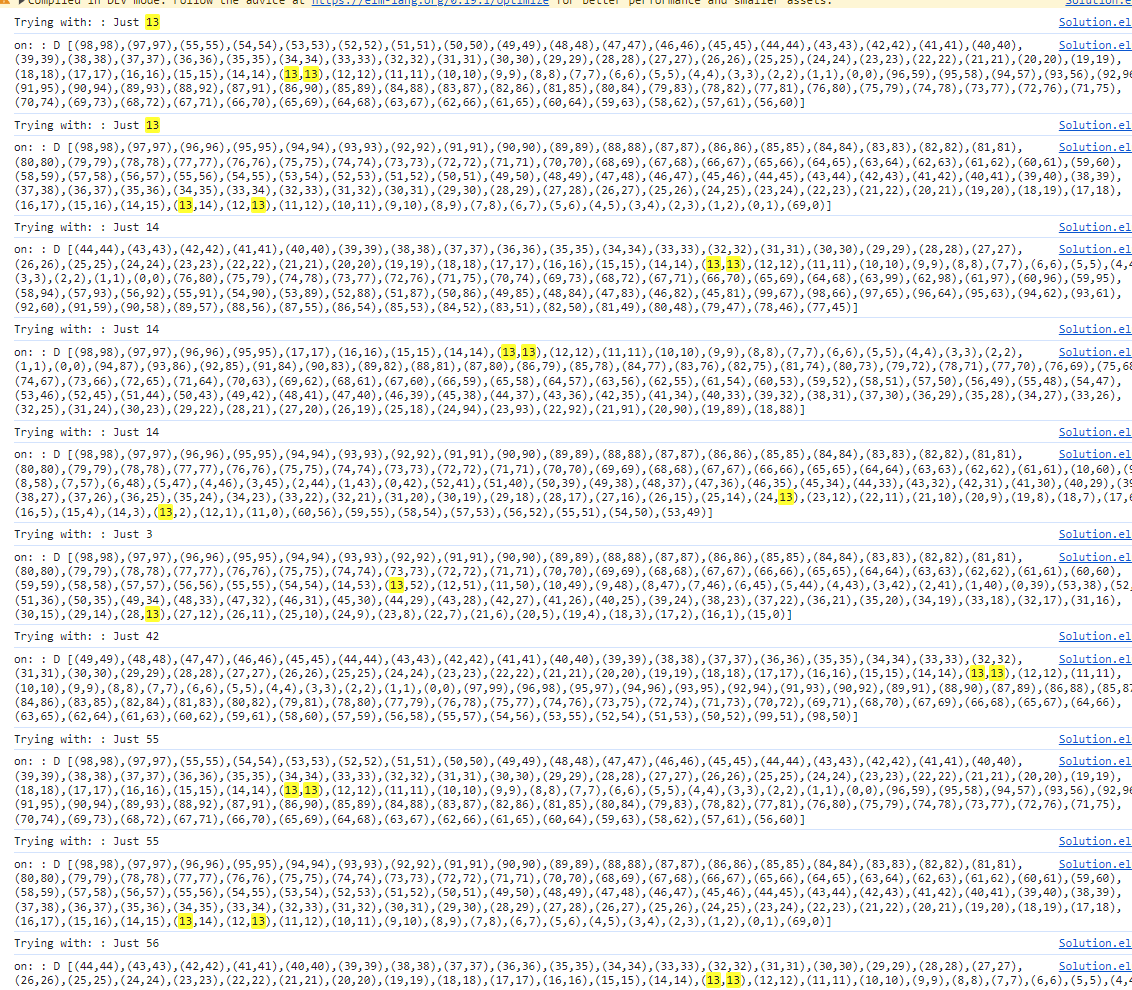
I had to cross-reference the listing with the sample data, and found out that Dicts (Hash Maps) return the listing of values not in the same order they got them as input and for a function like foldL which relies on the order, this is devastating
traverse : Mapping -> Int -> Maybe Int
traverse maps s =
List.foldl mapId (Just s) <| Dict.values maps
I had to change typing of Mapping from a Dict of Dicts to a List of Dicts. To stick to the requirements of the context in which I use it.
type alias Mapping = List (Dict Int Int)
Now it works!
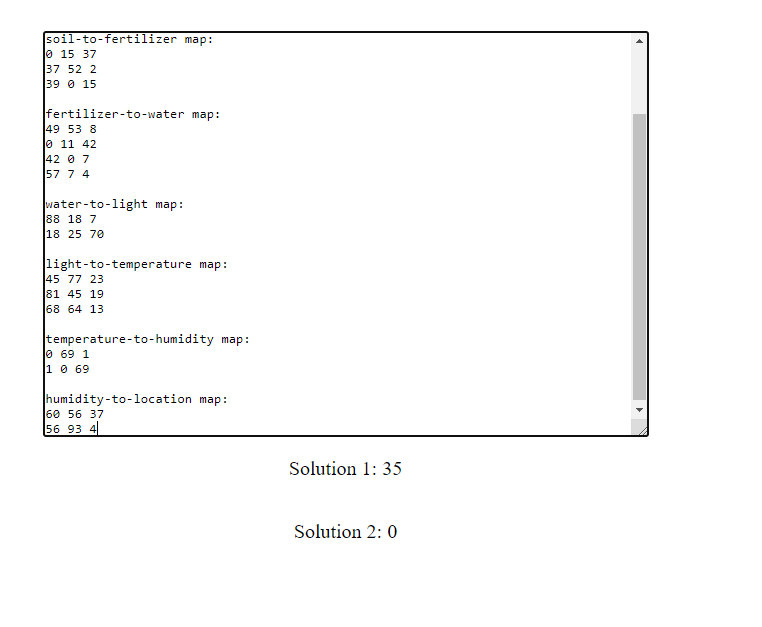
Now with the real dataset
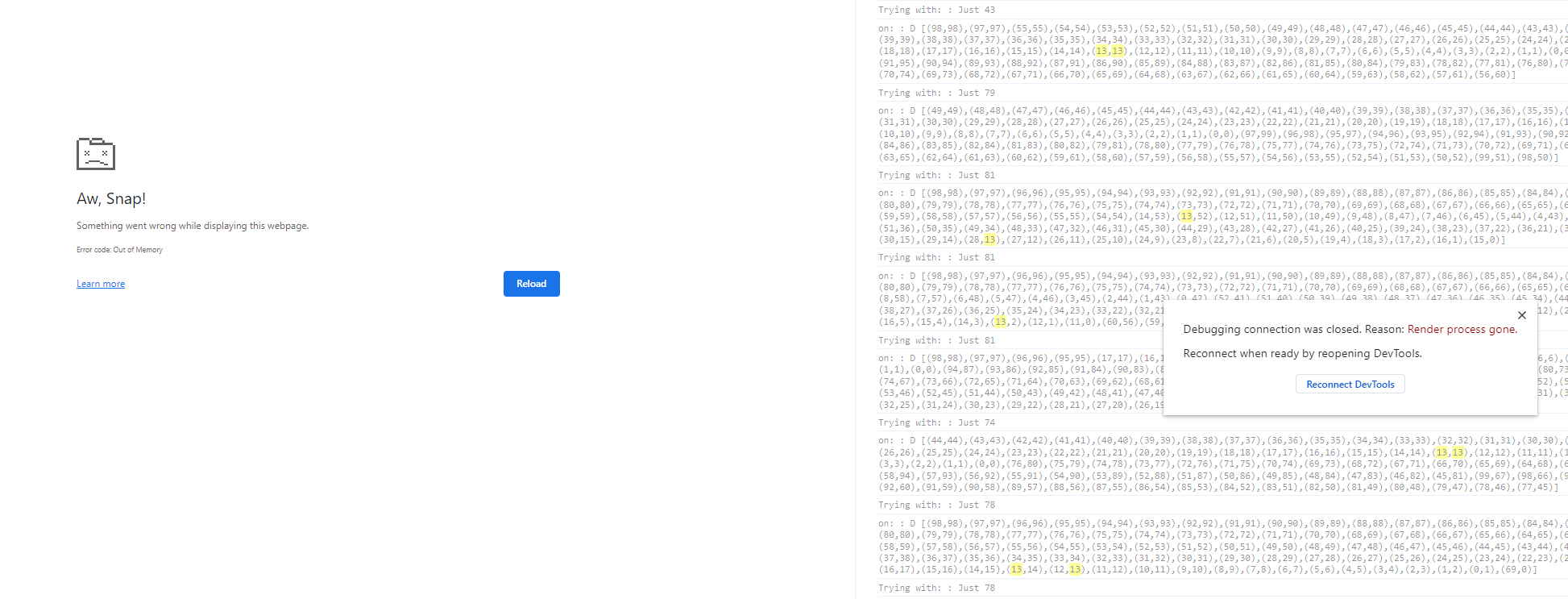
I have the suspicion that the numbers and therefore the ranges are way to high and blows up the memory.
Working around the big numbers
I have tried to get the lowest number before doing the range fill step to avoid allocating unused positions.
...
ranges =
List.tail lines |>
Maybe.withDefault [] |>
List.map parseNum |>
List.map (\b -> List.map (\a -> if a > minNum then a - minNum else a) b) |>
List.map listToRange |>
Maybe.values |>
List.map rangeToMapping |>
List.concat
...
solve1 : Structure -> Int
solve1 str =
List.map (traverse str.mappings) str.seeds |>
Maybe.values |>
List.minimum |>
Maybe.withDefault 0 |>
(\a -> str.root + a) -- add minimum common number back on top of result
But still OOM Exception. It is getting late, and I am tired.
Looking around in the community, most people either use very performant languages like C, C++ or Rust. Or found a clever workaround (which in my case would mean rewriting my entire code using some hacky solution), or had Haskell and its power of lazy evaluation and not even had to bother about this problem. I am happy that my algorithm works for the sample data at least. I think I've reach the limits with elm in terms of resources.
Takeaway
I should start my reasoning from the end to the front to determine the best data structure for my algorithm. I overthought the data modeling (just because it is so elegant and therefore fun in elm). Start thinking more efficiently and find a compromise between fast and elegant solution.
Coming Back after Day 6's morale boost
So turns out, that I am not a total waste of a human being, as I felt yesterday, but that sometimes the little elves in elf land are very very mischievous and seeing how many people struggled and had to "bruteforce" their way to victory I feel a bit more empowered. Mind you, I have no background in computer science, when it comes to hardware limitations in algorithmic design I hit my limit. Abstraction, modeling, reasoning, building systems, following idioms, breaking down problems. All not a problem. I am after all a design educated person and love analyzing and model the world around me in terms of systems. But algorithmic complexity and working around it, has to be a blind spot of mine. But I think acknowledging my weakness is a good step towards improvement. Enough sobbing, let's get back to it!
Yay! 🎅
So what I learned from Day 6 is, that I need to be concise, estimating the best route to the solution beginning from the end and keeping in mind efficiency traps along the way.
My first change will be to pre-parse my input into blocks and work from there. I will not create maps this time, and I will try to figure out a function to calculate the "open" ranges in the mapping. Hopping from one id to the next. It might take longer than pre compiling. But I like my Ram and I would love to have it a bit longer.
But first a cigarette!
And... a little detour over to day 2. Then another cigarette!
Starting at the end
Now. I deleted the entire code except for my boiler plate elm architecture. Let's get to it shall we?
solve1 : String -> Int
solve1 str =
let
blocks = String.split "\n\n" str
seeds = List.head blocks |> Maybe.withDefault "" |> parseNum
mappings = List.tail blocks |> Maybe.withDefault []
in
seeds |>
List.map (traverseMapping mappings) |>
List.minimum |>
Maybe.withDefault 0
traverseMapping : List String -> Int -> Int
traverseMapping maps seed = 0
I just want to reiterate on my observation that when reasoning from the bottom up in a functional programming language, you never feel lost. Since everything is tied together by type signatures you are always sure to have a result and just need to fill in the blanks. This is a very motivating force. Eventho we don't know yet what exactly traverseMapping will do, we can understand the remaining algorithm. And once I implement traverseMapping everything else falls into the right place.
traverseMapping : List String -> Int -> Int
traverseMapping maps seed =
List.foldl mapId (Just seed) maps |>
Maybe.withDefault 0
mapId : String -> Maybe Int -> Maybe Int
mapId mapping in_id =
let rows = String.lines mapping |> List.tail |> Maybe.withDefault []
in
List.foldl findInRow in_id rows
findInRow : String -> Maybe Int -> Maybe Int
findInRow row from =
let numbers = Debug.log "Numbers: " <| parseNum row
in
Nothing
Now I have this setup. The Idea is to use find Row to parse the row do some mathematical indexing, if the target id is not in the range it returns nothing, if at the end it is nothing it will match with the remaining "natural" mapping. However I have not thought it through yet fully.
At least now I can introspect the data without the computer blowing up:
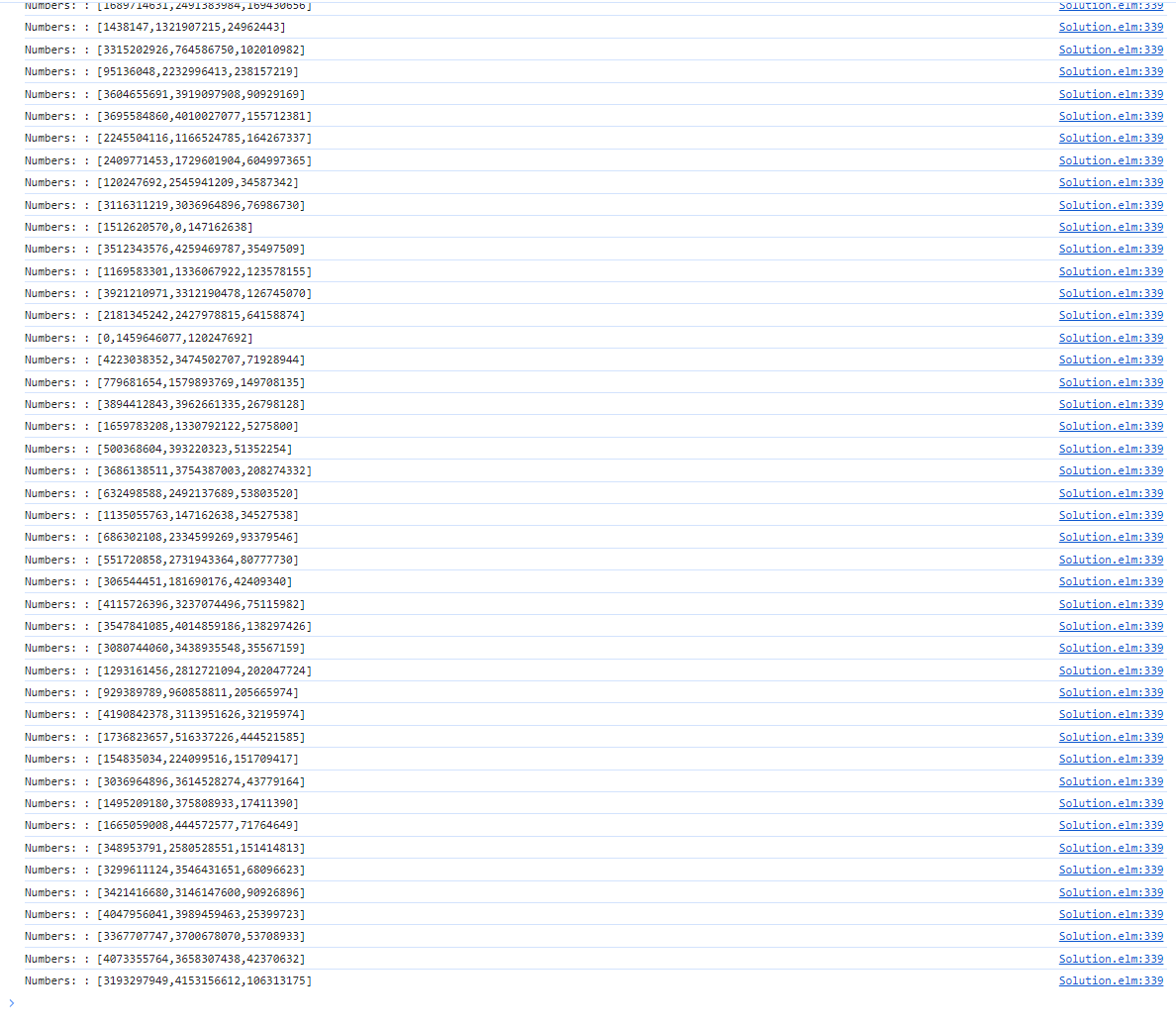
And I am calling this a small success already. This shows me, that the data when kept within a smaller scope can be handled just fine.
findInRow : String -> Maybe Int -> Maybe Int
findInRow row id =
let
numbers = parseNum (Debug.log "row" row)
in
Debug.log "Result in Row: "
(Maybe.andThen (\real_id ->
case numbers of
[to, from, range] ->
if real_id >= from && real_id <= from + range - 1
then Just (real_id - from + to)
else Nothing
_ -> Nothing)
(Debug.log "With -> " id) )
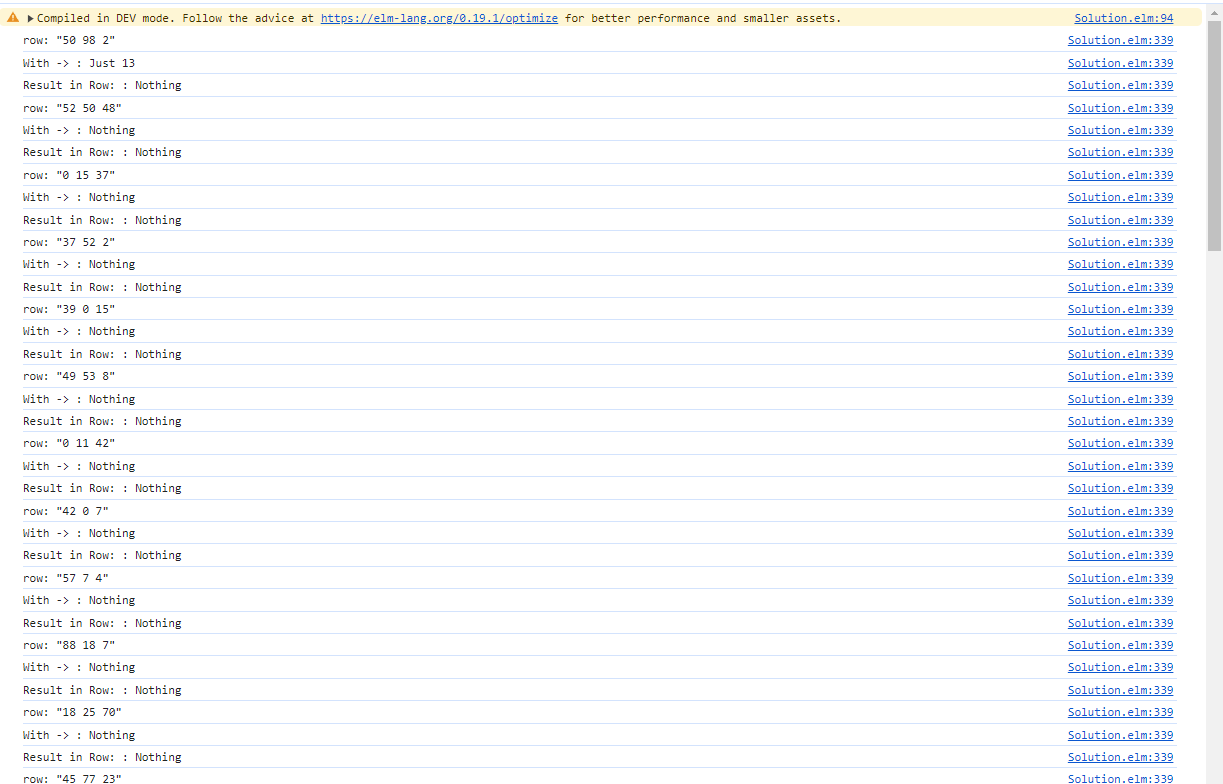
Here we can observe the behavior of the traversal.
Keep in mind, this new implementation does not account for the values outside of the explicitly listed ranges, here by called the "outside range". This is the reason why most of the traversal returns "Nothing".