AOC23 - 4 December
2023-12-4
Well, last night's puzzle session taught me a lesson. Focus more on the code, don't go over board with the visualization and also keep the explaining to a minimum. As much as I love to share the entire thought process. It is extremely time consuming.
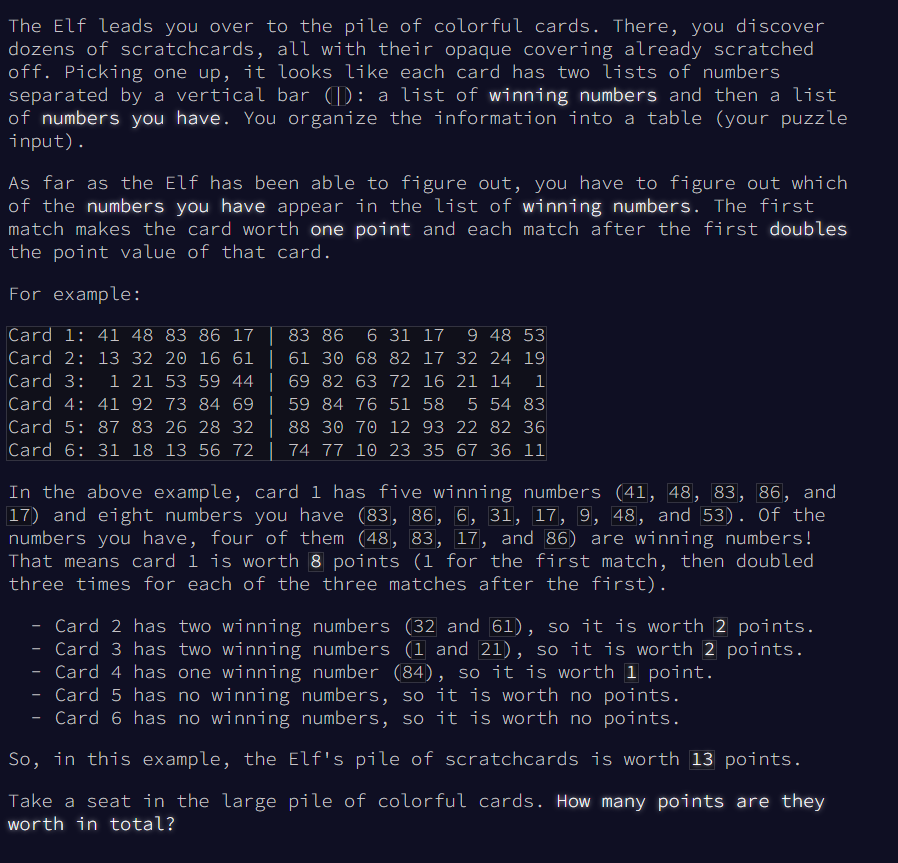
Let's begin analyzing the problem, then I'll code and report after I have a solution, or any impactful event.
So after a cigarette in bitter cold weather, I had no time to think about the problem at hand, because other things kept my mind busy. Unfortunately as a full time student, part-time freelancer, part-time game dev during the work week the Advent of Code should stay a little brain exercise and not a full-day activity, and what costs the most time is writing about every step. So from now on I will only post the reasoning before solving it, the data structure and the implementation of the algorithm, after solving it.
As an additional challenge I will try to express the core algorithm in one function and make it as concise as possible. That should be possible with Elm.
Right?
Data Model
So we have a list of cards, each with numbers. I have to match the numbers of the left side with the numbers on the right side of the "|" and count the matches. Add the counts together to have the points.
This puzzle screams Regex. But for now here is the Data model and core functions:
type alias Card =
{ left : List Int
, right : List Int
}
solve : String -> Int
solve str =
String.lines str |>
List.map (\a -> String.split ":" a |> List.reverse |> List.head |> Maybe.withDefault "") |>
List.map parseCard |>
List.map countMatches |>
List.sum
parseCard : String -> Card
parseCard str =
{left = [], right = []}
countMatches : Card -> Int
countMatches card = 0
Main Algorithm
This is the implementation of Parse Card:
parseCard : String -> Card
parseCard str =
let
match_numbers =
Maybe.withDefault Regex.never <|
Regex.fromString "\\d*"
parse_numbers str_n =
Regex.find match_numbers str_n |>
List.map (\a -> String.toInt a.match) |>
Maybe.Extra.values
numberLists = String.split "|" str
in
{ left =
List.head numberLists |>
Maybe.withDefault "" |>
parse_numbers
, right =
List.reverse numberLists |>
List.head |>
Maybe.withDefault "" |>
parse_numbers
}
this is how I count matches:
countMatches : Card -> Int
countMatches card =
List.filter (\a -> List.member a card.right) card.left |>
List.length
I misread the prompt, I need to double the point for each match. That is basically binary.
Here is the ammended solution.
countMatches : Card -> Int
countMatches card =
List.filter (\a -> List.member a card.right) card.left |>
List.length |>
(\a -> if a > 1 then 2^(a - 1) else a)
If it is 1 or 0 it stays 0. If it is higher than 1 we just take the power of 2, being the accumulated result of multiplying by 2.

Let's go for part 2 then.
Part 2
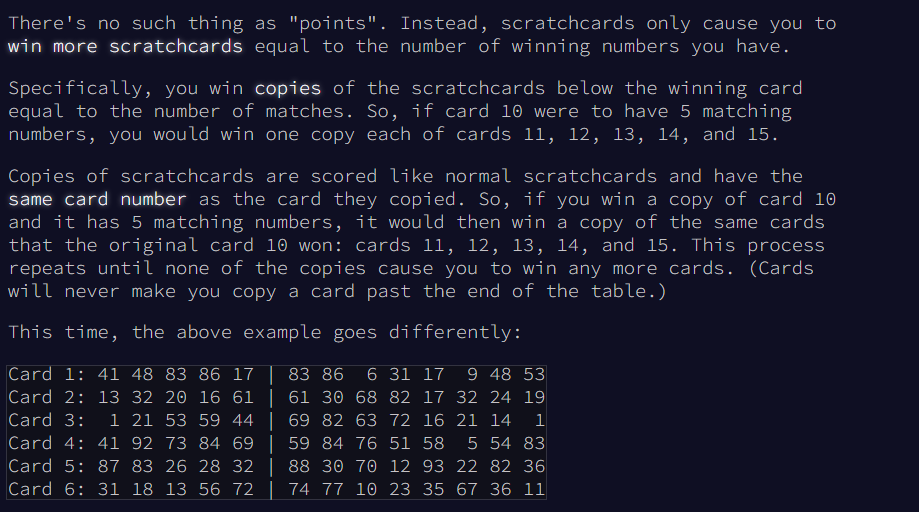
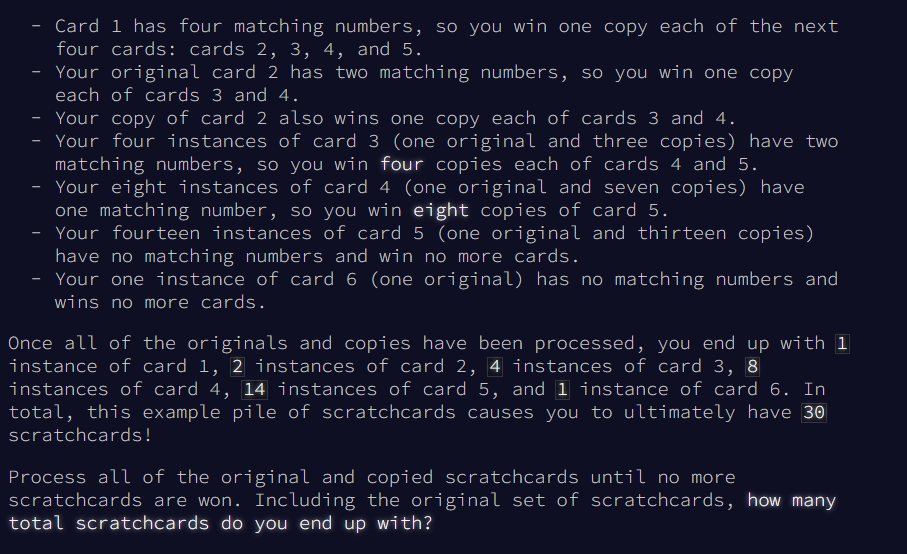
Let's refactor the code a bit for reusability
countMatches : Card -> Int
countMatches card =
List.filter (\a -> List.member a card.right) card.left |>
List.length
countPoints : Card -> Int
countPoints card =
countMatches card |>
(\a -> 2^(a - 1) else a)
Also to solve this every card needs to be aware of the next cards, so I need to first parse the entire input and work straight from a List of Cards.
solve : String -> Int
solve str =
let
list_of_all_cards =
String.lines str |>
List.map (\a ->
String.split ":" a |>
List.reverse |>
List.head |>
Maybe.withDefault "") |>
List.map parseCard
in
List.map (evaluate list_of_all_cards) list_of_all_cards |>
List.sum
evaluate : List Card -> Card -> Int
evaluate all_cards card =
getCopies all_cards card |>
List.map countPoints |>
List.sum
getCopies : List Card -> Card -> List Card
getCopies list_of_all_cards card =
let
cards_array = Array.fromList list_of_all_cards
from_card =
Array.indexedMap (\i a -> (i, a)) cards_array |>
Array.filter (\a -> Tuple.second a == card) |>
Array.map (\a -> Tuple.first a) |>
Array.get 0 |>
Maybe.withDefault 0 |>
(\a -> a + 1)
to_card =
from_card + (countMatches card)
in
Array.slice from_card to_card cards_array |>
Array.toList
This however is wrong. After reading again, I realized that the process is recursive. Oh dear.
Also I only have to count the cards.
I have a new algorithm which uses recursive folds to collect the cards:
collectCards : List Card -> Card -> List Card -> List Card
collectCards list_of_all_cards card_to_process collected =
let
won_copies = getCopies list_of_all_cards card_to_process
new_collection = List.append collected [card_to_process]
in
if List.length won_copies > 0
then List.append new_collection <| List.foldl (collectCards list_of_all_cards) won_copies won_copies
else [card_to_process]
Before unleashing it onto the full data set, I wanted to do a proof of concept with the sample data. But no matter how I twisted and turned my function I couldn't match their result. When I analyzed my intermediate output data, of the copies of each processed card (including the one from copies), I realized that my card 4 returns no copies.
...
in
if matched_cards >= 1
then
Array.slice from_card to_card cards_array |>
Array.toList
else
[]
...
Found the culprit! I checked if matched_cards were "> 1" which would exclude a single match. Now the sample data works. Let's unleash it on the real input set and get done with it!
5 min. later (it took so long to process) I had my answer:
Take Away
I am pretty fast in structuring my data and algorithm by now in elm. However my next area I need to improve is to reduce algorithmic complexity. This however is not due to my lack of knowledge of the language, but a sign of weakness in algorithm design I need to work on. I rely too much on abstraction and modeling the semantics according to my line of thoughts, totally overshadowing actual processor cycles. I think the recursive fold is hard to avoid, but I could reduce the iterations on simple steps like finding matching indexes, etc... I might have to model data a bit smarter. But nevertheless we came to a solution.