AOC23 - 1 December
2023-12-1
So this year I decided to indulge into the Christmas Hype train and partake into the Advent of Code. I might use this to learn more about 'Elm'. So first things first let's put in a christmas playlist and turn up the volume.
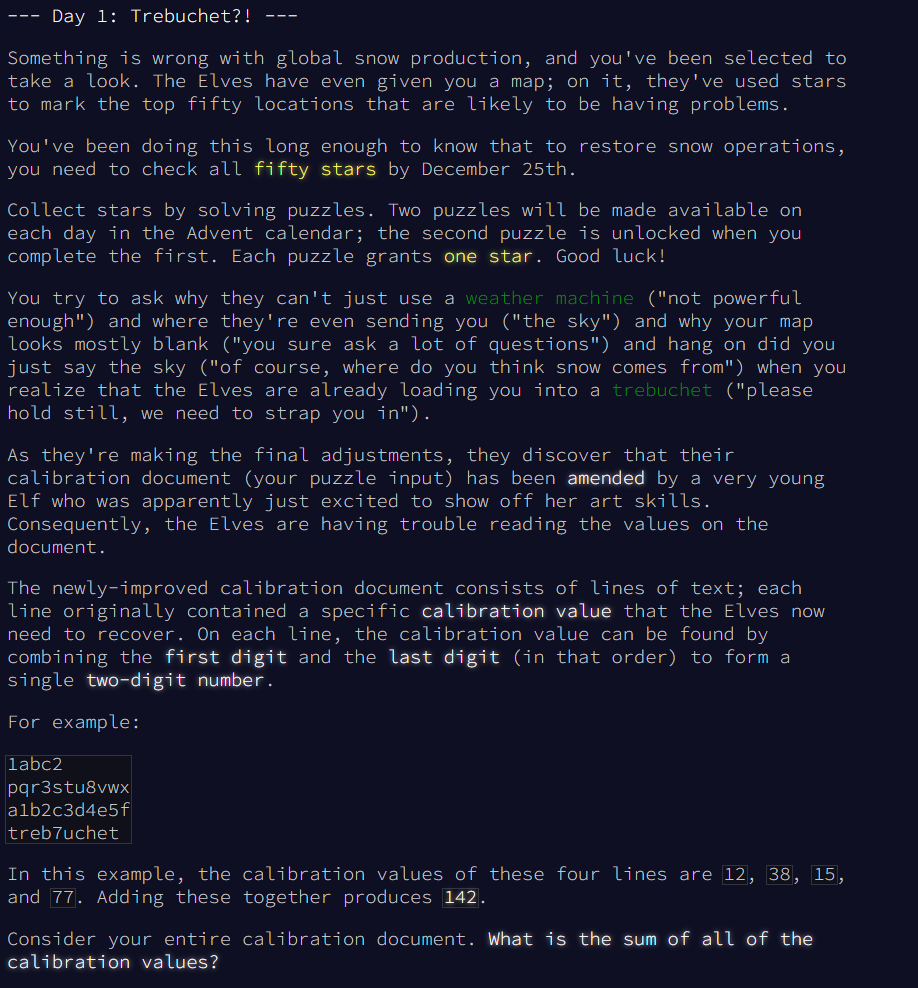
This instructions boil down to:
- Lines of strings, each with two digits inside
- Extract two digits on each line
- Combine them and convert them to a number
- Sum the resulting numbers
Setup
Let's start! First of all I create a new folder for the advent of code:
cd .\playground\
mkdir advent_of_code
cd .\advent_of_code\
mkdir 2023
cd 2023
mkdir 1
cd 1
code .
This brings me into vscode where I am going to create a basic elm setup. To avoid having to setup everytime, I will initialize elm inside of 2023.
elm init
After setting up git and Elm I am good to go. (I will show this boilerplate code only once, in this post, from then onwards I will only write the relevant Elm code)
module Main exposing (..)
import Html
import Browser
main =
Browser.sandbox
{ init = init
, view = view
, update = update
}
init =
0
view _ = div [] []
update _ _ = 0
So this is the boilerplate code to test, everything is setup correctly (I used this occasion to configure this as a snippet for future use). Ah no...
import Html exposing (..)
This would have thrown an error right out the gates.
Ok let's try to compile
elm reactor
Navigating on localhost:8000 to my "1/Main.elm" produced no error, we are good to go!
This is where the learning begins.
The algorithm is straight forward. And this is nice, because this is about learning the language semantics and syntax and apply it to our abstract recipe, learning how to do the things in the "elm way" along the way.
- Read text and divide it into lines
- Read each line and
- identify the first two digits, discarding the rest (We will see that this is wrong)
- for each two digits combine them as strings
- convert them to an integer
- sum the integers of each line to a total sum
Read text and divide it into lines
Since Elm is a language for the Web, frontend specifically, I will try to solve each puzzle with a UI. The most idiomatic way therefore would be to add a text box, where we can paste in the code to be parsed for the first step.
Let's do it!
So first of all we need to display a textbox, that sends a message to the browser sandbox, when the text has been changed.
module One.Solution exposing (..)
import Html exposing (..)
import Browser
main : Program () Model Msg
main =
Browser.sandbox
{ init = init
, view = view
, update = update
}
type Msg = CodeChanged String
type alias Model =
{ inputCode : String
, result : String
}
init : Model
init =
{ inputCode = ""
, result = ""
}
view : Model -> Html.Html msg
view model =
div []
[ textarea []
[]
, p [] [text model.result]
]
update : Msg -> b -> b
update msg model =
case msg of
CodeChanged a ->
model
In the meantime I relocated the folders inside "src", because the linter was not working.
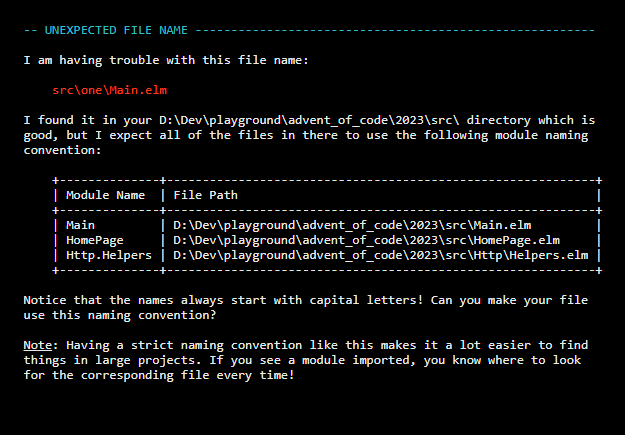
Now got this error. Which is quite frustrating, not gonna lie.
I had to fix it by renaming my folder from 1 to "One" and change the Module name to "One.Solution". Oh well. Let's continue.
We have a text box!

And I inserted the code.
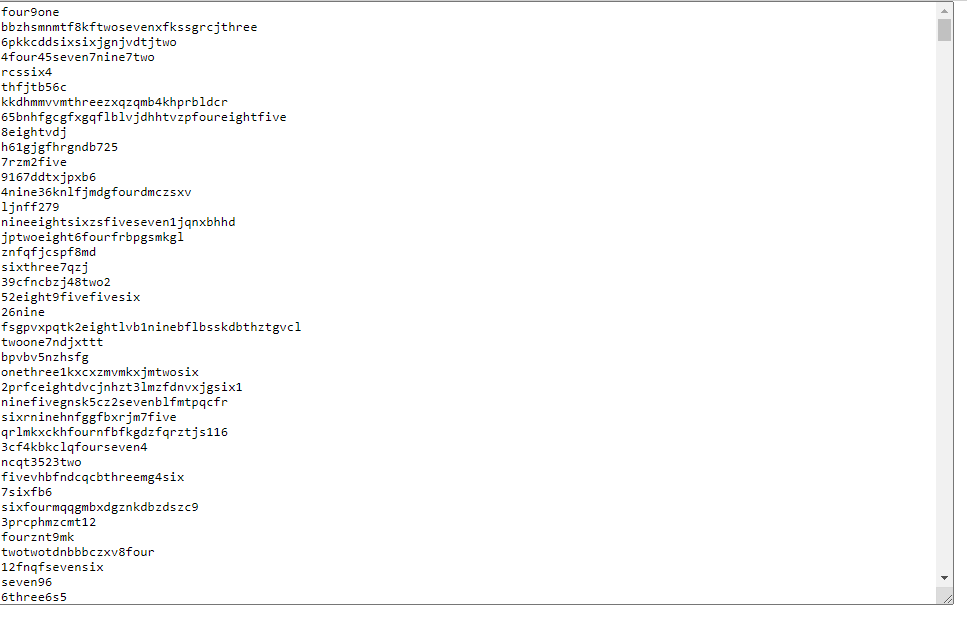
Now I noticed something. Not only does every line have a digit. It also has strings spelling out the number. How very ironic, that this is so closely related to the error I just had a minute ago, and the solution to my problem, being the very thing making this puzzle a lot harder. I read the prompt again. Fortunately they do not ask of us to parse the literal spelling of digits. But I just realized that I need to combine the first and last digit of one line, using the same digit twice should it be only one in the line.
Alright!
To finish this step, we need to get the textarea to send a message to the Update loop on change.
onInput: (String -> msg) -> Attribute msg
"onInput" seems to be a function, taking a function that turns a string to something else, and turning everything into an attribute. The easiest thing would be to create such a function and pass it.
receiveChange : String -> Msg
receiveChange change = CodeChanged change
Ah no, turns out, in Elm similar to Haskell your type Constructor is like a function and I can use pointless notation and just pass it directly to "onInput"
...
[ textarea
[onInput CodeChanged
]
[]
, p [] [text model.result]
]
...
Unfortunately I now have a compile error. It was related to the discrepancy of "Hmtl msg" and "Html Msg". Which is very frustrating. I thought msg is a type variable accepting anything, but apparently my user defined Msg is not one of such types it likes. I had to change my type annotations.
Last thing to do is take on this case in my Update function and we are done with step 1
update : Msg -> Model -> Model
update msg model =
case msg of
CodeChanged a ->
{model | result = processCode a |> String.fromInt}
processCode : String -> Int
processCode change = 0
First of all updating records is straightforward, and I can selectively update result by separating the record name and it's field with "|". With the "|>" operator (which I learned about in my previous program study) I can pipe my result into a conversion function and be done. Neat.
Now for step 2, we have to split the entire String into lines based on a line-break.
Every programming language should have that implemented, so let's find it in the API.
split : String -> String -> List String
lines : String -> List String
I have two options. And since "lines" is essentially a "split" with newline characters it reflects more the semantics we are aiming for. We are done with step 2.
Elm (being a functional language) always needs to return a value, so for now our process function looks like this:
processCode : String -> Int
processCode change = List.length <| String.lines change
Extract Numbers from Lines and Sum them
So here are the ammended steps that our process function needs to do:
- Map over each line
- For each line filter for digits
- get the first and last entry in the list
- append them together to form a new number
- convert the string to a number
- sum the mapped numbers
Since we are in a functional language, we will use higher-ordered functions and start from the last step. Sum our numbers.
sum : List number -> number
Now is time for map and anonymous functions. Let's see how to do them in Elm.
square = \n -> n^2
Ok, like Haskell. However if I already convert my digit extraction function from "String -> String" to "String -> Int" I can pass it in a pointless style, resulting in this beauty:
processCode : String -> Int
processCode change =
List.sum
<| List.map extractDigits
<| String.lines change
Changing the order, we can read it in a more imperative style:
processCode : String -> Int
processCode change =
String.lines change |>
List.map extractDigits |>
List.sum
There we go.
Now for the digit extraction!
What I need is a filter function over each String, interpreting String as a List of Char (if that is possible?) And applying this:
isDigit : Char -> Bool
So let's read about String and Chars.
Yup.
toList : String -> List Char
My Intuition did not deceive me. A String can be converted to a List of Char.
Now we use filter.
filter : (a -> Bool) -> List a -> List a
If we filter every char for a digit we will have a list of chars being digits.
Now the trick is to use the same list for both queries. First pick the first entry, and then pick the last entry. If the list only contains one entry it will effectively be picked twice!
head : List a -> Maybe a
Head returns the first entry, if there is one, and Nothing (a compound type handling null cases) if there is none. Now a List in functional programming is usually a linked list, of the head entry concatenated with it's tail. So getting the last entry in that form would be a pain. Fortunately list has this function:
reverse : List a -> List a
So now we have all the pieces.
Let's put them all together:
extractDigits : String -> Int
extractDigits line =
let digits =
String.toList line |>
List.filter isDigit
in String.toInt <|
(String.fromChar <| head digits)
++
(String.fromChar <| head <| reverse digits)
Now the only obstacle remaining is this error message:
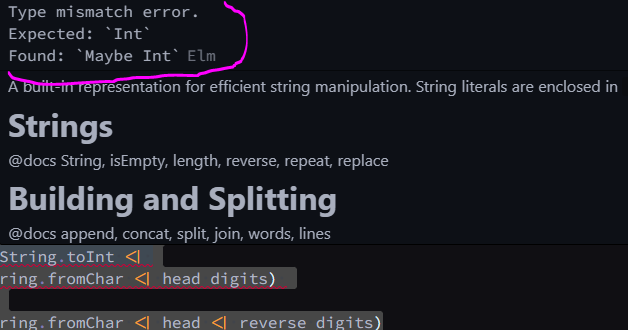
Because we have a Maybe Int, since our list could be empty.
Now I need to learn how to resolve a Maybe value.
Syntax / Pattern Matching To the rescue!
With that I created my self a little helper function:
solveInt : Maybe Int -> Int
solveInt value =
case value of
Nothing -> 0
Just n -> n
Let's slot that in and be done.
Ah, it throws a type error. Of course. Digits is already a List of Maybe Char.
values : List (Maybe a) -> List a
This is an amazing function, which unfortunately is part of an external library.
elm install "elm-community/maybe-extra"
...
import Maybe.Extra
...
Which brings us to the final result
extractDigits : String -> Int
extractDigits line =
let digits =
String.toList line |>
List.filter Char.isDigit
in solveInt <| String.toInt <|
String.fromList <|
Maybe.Extras.values
[List.head digits, List.head <| List.reverse digits]
solveInt : String -> Int
solveInt value = Maybe.withDefault 0 <| String.toInt value
By the way this
case value of
Nothing -> 0
Just n -> n
Is already handled by a neat function called "Maybe.withDefault" with this signature
withDefault : a -> Maybe a -> a
Let's make it more readable
extractDigits : String -> Int
extractDigits line =
let digits =
String.toList line |>
List.filter Char.isDigit
in
[List.head digits, List.head <| List.reverse digits] |>
Maybe.Extra.values |>
String.fromList |>
solveInt
Beautiful!
Let's test it.

Seems to work.

Yay!
here is the finished solution and the repo where I will be submitting my solutions for every day.
Take Away
Elm is cool. It is a domain-specific language for web and a simpler version of Haskell. It forces you to think in terms of a model, an update and view cycle, already incorporating the UI elements with the code. The type system of elm enforces you to think of your code like a pipeline, or rather a puzzle box, where the signature of one functions guides to the next. This was a very fun experience.
See you on the next cha...
Wait a second.
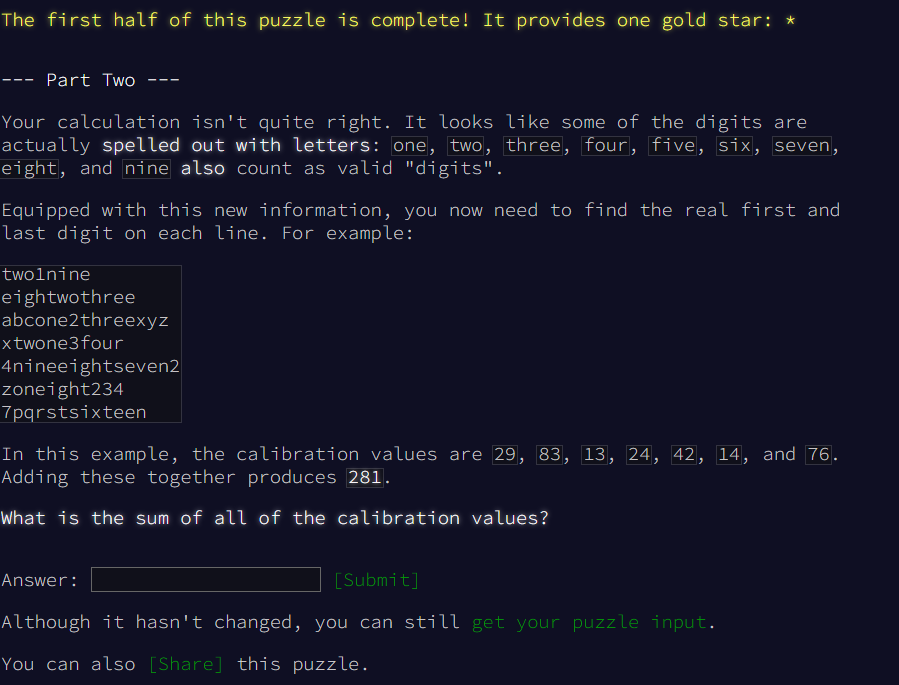
You must be f*** kidding me. And I even predicted it.
Oh well...
Amending the Algorithm, once again
This requires me to think completely differently about it now.
Now the changed steps would be.
...
iterate over each line joining together characters
discard characters that do not match
but then how would I know, when one starts and the other finishes?
Help.......
Ah no, wait. Regular expressions solve exactly this problem. A neat level of abstraction. We need to filter for one, two, three, four, five, etc... and digits. Convert the spelled out versions and insert them. Time for a cigarette to think this through.
So first of all, let's implement the reading of "literal" numbers.
readNumber : String -> Int
readNumber word =
case word of
"one" -> 1
"two" -> 2
"three" -> 3
"four" -> 4
"five" -> 5
"six" -> 6
"seven" -> 7
"eight" -> 8
"nine" -> 9
_ -> 0
To make it semantically and idiomatically more correct let's talk elm:
readNumber : String -> Maybe Int
readNumber word =
case word of
"one" -> Just 1
"two" -> Just 2
"three" -> Just 3
"four" -> Just 4
"five" -> Just 5
"six" -> Just 6
"seven" -> Just 7
"eight" -> Just 8
"nine" -> Just 9
_ -> Nothing
Ok. Nice. Let's learn regular expressions in Elm.
lowerCase : Regex.Regex
lowerCase =
Maybe.withDefault Regex.never <|
Regex.fromString "[a-z]+"
This example tells us everything we need. Since we can build Regex from a string, I am going to refactor everything a bit more neatly to keep it dry and more abstract:
literalDigits = Dict.fromList
[ ("one", 1)
, ("two", 2)
, ("three", 3)
, ("four", 4)
, ("five", 5)
, ("six", 6)
, ("seven", 7)
, ("eight", 8)
, ("nine", 9)
]
readNumber : String -> Maybe Int
readNumber word = Dict.get word literalDigits
And we learn about Dict along the way.
Let's build our regular expression.
But first, what is Match?
type alias Match =
{ match : String
, index : Int
, number : Int
, submatches : List (Maybe String)
}
Ah, beautiful, ok so Match.match gives us the "real" matched substring. With this new knowledge I will attempt to implement a new number matcher:
findNumbers : String -> List (Maybe Int)
findNumbers line =
let
query =
Maybe.withDefault Regex.never <|
Regex.fromString <|
String.append
(String.join "|"
(List.map (\a -> "(" ++ a ++ ")")
(Dict.keys literalDigits))
) <| " |\\d"
matches = Regex.find (Debug.log "regex: " query) line
in List.map
(\match ->
if (String.length match.match) > 1
then readNumber match.match
else String.toInt match.match)
matches
Ok. This is a mouthful, let me help you follow along.
First of all we build our Regex query, by taking the keys of our dict "literalNumbers" which is "one", "two", "three", etc... and join it with "\d" so that we match the previous case of normal digits as well. We wrap the spelled out digits in "()" to group them and join them by "|". A little metaprogramming so we can use our dict as argument for our regex. Then we query our line for any matches. Finally in the body we map over our matches list, check if the string is bigger than 1 which represents a "literal" number and use our readNumber function, if not, it is a String digit and we use the conversion function. Both of them return Maybe Int, which gives us a List of Numbers or Nothing.
Now we need to integrate it into our previous code and we are done. Puuu.
extractDigits : String -> Int
extractDigits line =
let digits =
findNumbers line |>
Maybe.Extra.values |>
List.map (\a -> String.fromInt a)
in
[List.head digits, List.head <| List.reverse digits] |>
Maybe.Extra.values |>
String.concat |>
solveInt
I only had to replace the List filter on "isDigit" with our new function and instead of joining chars at the end we 'concat' Strings. So effectively I had to change 2 lines of code -> Power of functional programming.

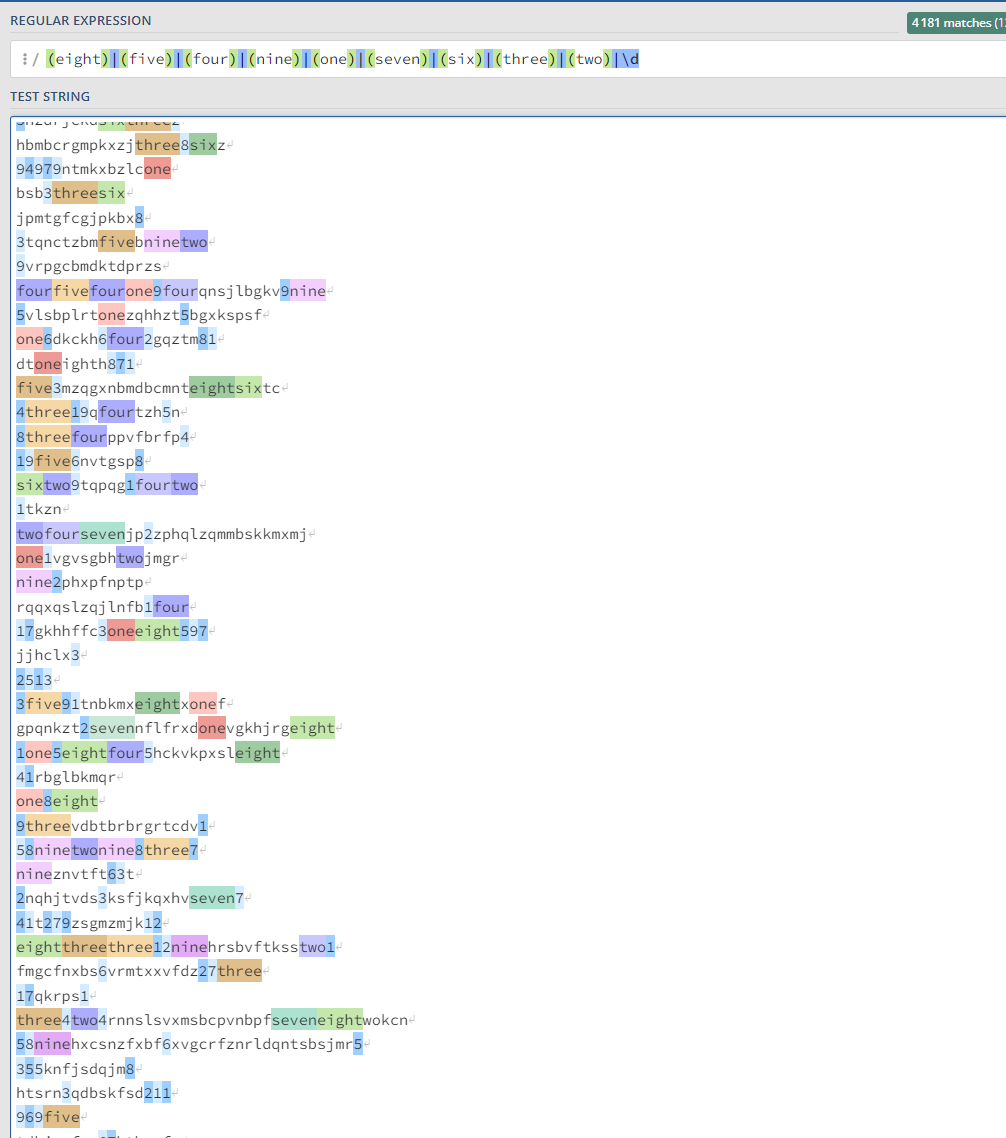
Damn it. Checking the log I can see that my regex is invalid.
query: : "(eight)|(five)|(four)|(nine)|(one)|(seven)|(six)|(three)|(two) |\\d"
Let's debug the regex then. All the number seem to be there, altough in a weird order (thanks to being a dict and not a list, ordering them alphabetically). I have to correct it a bit:
"(eight)|(five)|(four)|(nine)|(one)|(seven)|(six)|(three)|(two)|\d"
Seems to be correct at least. The documentation says:
Note: There are some shorthand character classes like
\wfor word characters,\sfor whitespace characters, and\dfor digits. Make sure they are properly escaped! If you specify them directly in your code, they would look like"\\w\\s\\d".
So I intuitively did it correctly, however, still invalid. After double checking a theory of mine:

Turns out my only mistake was a space when joining the "\d" part. Other than that no bugs.
Why? Because the safe type system of elm caught any other mistakes along the way. I did not have to check the state of intermediate operations once, with the exception of the failed regex. This is the true power of functional programming.
Now.
See you on the next chapter.
This time for real :)
(Btw, following the advent of code on a daily basis will not be my only challenge in december. My lovely girlfriend got me a an origami advent calendar with instructions to fold decorative paper into Christmas motives each day. Gonna report on that soon.)